前面已经介绍了ivy主要的术语和概念,现在是时候说明ivy如何工作的了。
不同位置下模块的通常周期
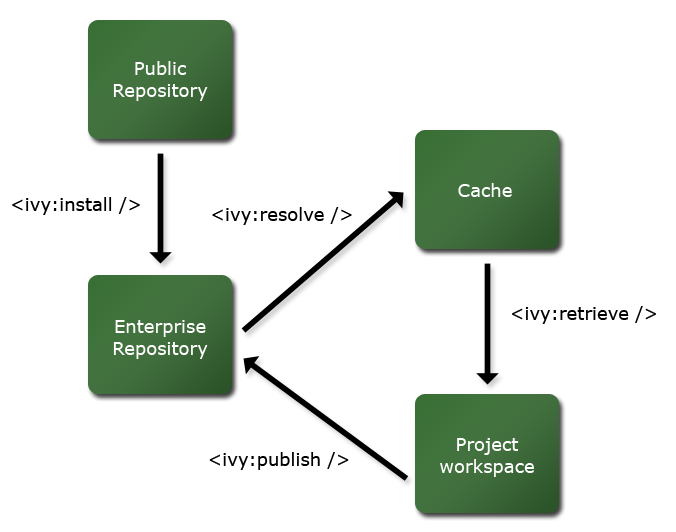
更多细节请查考ant任务。
一. 配置
ivy需要配置以便能够解析依赖。这个配置通常是通过配置文件来完成的,配置文件定义了一系列的依赖解析器。每个解析器能够发现ivy文件和/或制品,提供简单信息诸如组织,模块,修订版本,制品名字,制品类型和制品扩展名。
配置通常负责支出哪个解析器应该用于解析哪个模块。这个配置仅仅取决于你的环境,例如,在哪里可以找到模块和制品。
当没有给出任何配置时将使用默认配置。这个配置实用ivyrep来解析所有模块。
二. 解析
解析的时间是当ivy实际解析一个模块的依赖的时刻。它第一次需要访问模块的ivy文件来解析依赖。
然后,在这个文件中定义的每个依赖,它将请求适当的解析器(根据配置)来查找模块(例如,可能是一个ivy文件,或者如果没有找到ivy文件则是它的制品)。它同样使用基于缓存的文件系统以避免请求一个已经存在在缓存中的依赖。
如果解析器是组合而成的(例如链式或者双重解析器),为了查找模块可能实际调用多个解析器。
当找到依赖模块,它的ivy文件被下载到ivy缓存。然后ivy检查它是否有它自己的依赖,在这种情况下循环游历依赖图。
在整个游历过程中,尽可能快的进行冲突管理来阻止对模块的访问。
当ivy游历完整个图形,它请求解析器去下载每个依赖相应的不在缓存中并且不被冲突管理器排斥的制品。所有的下载都将加入到ivy缓存中。
最后,在缓存中将生成一个xml报告,让ivy可以容易的得知模块有哪些依赖而不必在此游历整个图型。
在这个解析步骤之后,可能有两个主要步骤:要不创建一个带有缓存中制品的路径,要不复制他们到另外一个目录结构。
三. 获取
在ivy中被称为获取的是从缓存中复制制品到另外的目录结构的行为。这个行为是通过使用模式来实现,模式为ivy指明这些文件可以从哪里复制。
为此,ivy使用缓存中它将获取的模块对应的xml报告来获知哪些制品应该被复制。
为了达到最佳性能它也检查文件是否没有被复制。
四. 从缓存中生成路径
在某些情况下,直接使用缓存中的制品更加合适。ivy能够使用在解析时生成的xml报告来生成一个包含所有需要的制品的路径。
当为IDE生成插件时这个方式特别有效。
五. 报告
ivy也可以生成方便阅读的依赖解析的报告描述。
这个是通过使用一个简单的xsl转换在解析时生成的xml报告来实现的。
六. 发布
最后,ivy可以被用于发布一个模块的特别的修订版本,以便这个版本在未来的解析中可以得到。这个任务通常被手工或者被一个持续集成服务器调用。